NYCJUG/2011-08-09
learning strategy, poker, agent-based simulation, functional programming, size of J
Location:: The Heartland Brewery, Empire State Building, 34th and 5th, NYC
An APL Family Tree
This illustration of APL's relation to kindred languages can be found here.
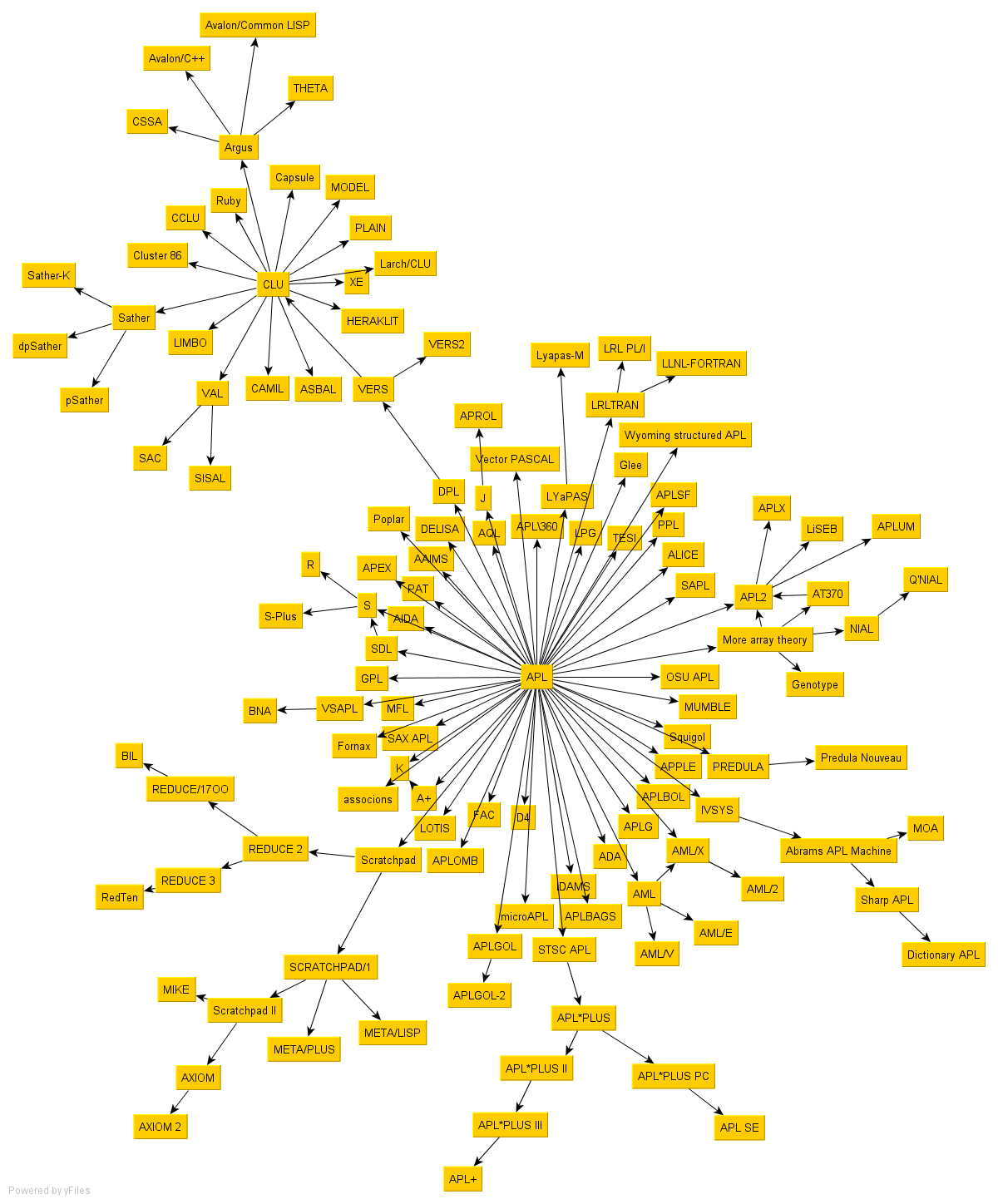{kind=link}

Beginner's Regatta
This is a much less code-based segment than normal where we consider part of the justification for terse notation by looking at the development of theories of learning and instruction over the past half-century or so. The more recent development has been informed by a better understanding of some of the limitations of human cognition.
Good Instruction
This paper, titled "Why Minimal Guidance During Instruction Does Not Work: An Analysis of the Failure of Constructivist, Discovery, Problem-Based, Experiential, and Inquiry-Based Teaching", purports to demonstrate that a theory of learning which was popular during the time APL was developed is not an effective technique. This was a technique advocated by Ken Iverson, that learning should be a minimally guided exploration starting from a few pieces of essential information. However, according to this research:
The goal of this article is to suggest that based on our current knowledge of human cognitive architecture, minimally guided instruction is likely to be ineffective. The past half-century of empirical research on this issue has provided overwhelming and unambiguous evidence that minimal guidance during instruction is significantly less effective and efficient than guidance specifically designed to support the cognitive processing necessary for learning.
Any instructional procedure that ignores the structures that constitute human cognitive architecture is not likely to be effective. Minimally guided instruction appears to proceed with no reference to the characteristics of working memory, long-term memory, or the intricate relations between them.
In the following sections, the paper outlines aspects of human cognitive architecture that affect learning. It starts by asserting
...long-term memory is now viewed as the central, dominant structure of human cognition. Everything we see, hear, and think about is critically dependent on and influenced by our long-term memory.
This assertion is supported by studied of chess expertise which found "...that expert chess players are far better able than novices to reproduce briefly seen board configurations taken from real games, but do not differ in reproducing random board configurations...." Summing up,
problem-solving skill emphasizes the importance of long-term memory to cognition. We are skillful in an area because our long-term memory contains huge amounts of information concerning the area. That information permits us to quickly recognize the characteristics of a situation and indicates to us, often unconsciously, what to do and when to do it. Without our huge store of information in long-term memory we would be largely incapable of everything from simple acts such as crossing a street (information in long-term memory informs us how to avoid speeding traffic, a skill many other animals are unable to store in their long-term memories) to complex activities such as playing chess or solving mathematical problems...our long-term memory incorporates a massive knowledge base that is central to all of our cognitively based activities.
Instructional Consequences of the Architecture of Long-term Memory
As the paper succinctly states "The aim of all instruction is to alter long-term memory. If nothing has changed in long-term memory, nothing has been learned.".
However, to do this, we must consider working memory, the part of the structure in which conscious processing occurs.
Working memory has two well-known characteristics: When processing novel information, it is very limited in duration and in capacity. We have known at least since Peterson and Peterson (1959) that almost all information stored in working memory and not rehearsed is lost within 30 sec and have known at least since Miller (1956) that the capacity of working memory is limited to only a very small number of elements. That number is about seven according to Miller, but may be as low as four, plus or minus one (see, e.g., Cowan, 2001). Furthermore, when processing rather than merely storing infoormation, it may be reasonable to conjecture that the number of items that can be processed may only be two or three, depending on the nature of the processing required.
The discussion continues by asserting that the
...interactions between working memory and long-term memory may be even more important than the processing limitations (Sweller, 2003, 2004). The limitations of working memory only apply to new, yet to be learned information that has not been stored in long-term memory. New information such as new combinations of numbers or letters can only be stored for brief periods with severe limitations on the amount of such information that can be dealt with.
The paper then goes on to note the contrast between working memory and long-term memory.
...when dealing with previously learned information stored in long-term memory, these limitations disappear. In the sense that information can be brought back from long-term memory to working memory over indefinite periods of time, the temporal limits of working memory become irrelevant.
This section concludes with the admonition that
Any instructional theory that ignores the limits of working memory when dealing with novel information or ignores the disappearance of those limits when dealing with familiar information is unlikely to be effective.
And goes on to also note that
problem solving, which is central to one instructional procedure advocating minimal guidance, called inquiry-based instruction, places a huge burden on working memory (Sweller, 1988).
From this we might conclude that anything which reduces the burden on working memory could aid problem-solving.
Conversely, since "...problem-based searching makes heavy demands on working memory" and "...that working memory load does not contribute to the accumulation of knowledge in long-term memory because while working memory is being used to search for problem solutions, it is not available and cannot be used to learn." This implies that "...instructional approaches requiring minimal guidance that are disconnected from much that we know of human cognition."
Research Comparing Guided and Unguided Instruction
The paper brings up research comparing the results of these different modes of instruction - guided versus unguided - but does not make an extensive review of this research. Instead, it touches on a review of these studies:
...Mayer (2004) recently reviewed evidence from studies conducted from 1950 to the late 1980s comparing pure discovery learning, defined as unguided, problem-based instruction, with guided forms of instruction. He suggested that in each decade since the mid-1950s, when empirical studies provided solid evidence that the then popular unguided approach did not work, a similar approach popped up under a different name with the cycle then repeating itself. Each new set of advocates for unguided approaches seemed either unaware of or uninterested in previous evidence that unguided approaches had not been validated. ... Mayer (2004) concluded that the “debate about discovery has been replayed many times in education but each time, the evidence has favored a guided approach to learning” (p. 18)
The paper goes on to cite some more recent research:
Stronger evidence from well-designed, controlled experimental studies also supports direct instructional guidance (e.g., see Moreno, 2004; Tuovinen & Sweller, 1999). Hardiman, Pollatsek, and Weil (1986) and Brown and Campione (1994) noted that when students learn science in classrooms with pure-discovery methods and minimal feedback, they often become lost and frustrated, and their confusion can lead to misconceptions.
This echoes a recent essay in the Daily Princetonian "Why won’t anyone teach me math?" in which a student bemoans her difficulty that "[t]he way the course was run did not at all set up students to succeed — or even learn math. For example, though we were provided with practice problems to prepare for our exams, we were never given solutions." Furthermore, their professor refused to provide solutions in spite of multiple requests because "not providing them was departmental policy".
Show and Tell
We show here how far we've gotten with our poker simulation code where we hope to implement parameterized playing strategies to study the effects of "loose" versus "tight" play.
Poker Simulation So Far...
We will show the most basic code as well as some examples of using it.
From "poker.ijs"
NB.* getPokerVars: get poker variables from file.
getPokerVars=: 3 : 0
vnms=. 'RH5i';'HRi';'HRbase'
NB. RH5i: SZ$integer vec: base 52 5-card hands ordered from worst to best.
NB. HRi: SZ$integer vec: (0{"1) type of hand (0-8); (1{"1) subtype when
NB. decoded by (0,HRbase)#:HRi.
(<PKRDIR) unfileVar_WS_&.>vnms
NB. Derive others: latter 2 larger but more directly useful.
SZ=: #RH5i [ RH5=: (5$52)#:RH5i [ HANDRATED=: (0,HRbase)#:HRi
NB. HRSUMMARY is hand-rank summary value from 0 to 8.975: linear valuation.
HRSUMMARY=: (0{"1 HANDRATED)+;(# %~ [: i. #)&.>(0{"1 HANDRATED)</. SZ$1
if. 0~:#vnms do.
if. -.IsFORKED do.
smoutput 'Vars created: ','.',~e2l vnms,'SZ';'RH5';'HANDRATED' end. end.
qts ''
)
NB.* bestHand: give major rank of best possible 5-card hand.
bestHand=: 3 : 0"1
assert. 5=#y
if. isNothing y do. 0 return. end.
if. isPair y do. 1 return. end.
if. is2Pair y do. 2 return. end.
if. is3ok y do. 3 return. end.
if. isOnlyStraight y do. 4 return. end.
if. isOnlyFlush y do. 5 return. end.
if. isFullHouse y do. 6 return. end.
if. is4ok y do. 7 return. end.
if. isStraightFlush y do. 8 return. end.
_1
)
isNothing=: 3 : 0
if. 2~:#$y do. y=. suitRank y end.
'suit rank'=. /:~&.><"1 y
NB. >1 suit, and no duplicates,
rc=. (1~:#~.suit)*.(#rank)=#~.rank
NB. and >1 apart, including special case of low Ace.
rc=. rc*.-.(1*./ . =2-~/\rank)+.1*./ . =2-~/\/:~(rank=12)}rank,:_1
)
isAnyFlush=: 3 : 0
if. 2~:#$y do. y=. suitRank y end.
*./2=/\0{y
)
isOnlyFlush=: 3 : 0
if. 2~:#$y do. y=. suitRank y end.
(isAnyFlush y)*.-.isAnyStraight y NB. Not straight flush
)
isAnyStraight=: 3 : 0
if. 2~:#$y do. y=. suitRank y end.
rc=. _1 *./ . =2-/\/:~rnk=. 1{y
if. 12 e. rnk do.
rc=. rc +. _1 *./ . =2-/\/:~(rnk=12)}rnk,:_1
end.
rc
)
isOnlyStraight=: 3 : 0
if. 2~:#$y do. y=. suitRank y end.
(isAnyStraight y)*.-.isAnyFlush y NB. Not straight flush
)
isPair=: 3 : 0
if. 2~:#$y do. y=. suitRank y end.
1 1 1 2-:/:~;#&.>(1,2~:/\/:~rnk)<;.1 rnk=. 1{y
)
is2Pair=: 3 : 0
if. 2~:#$y do. y=. suitRank y end.
1 2 2-:/:~;#&.>(1,2~:/\/:~rnk)<;.1 rnk=. 1{y
)
is3ok=: 3 : 0
if. 2~:#$y do. y=. suitRank y end.
1 1 3-:/:~;#&.>(1,2~:/\/:~rnk)<;.1 rnk=. 1{y
)
isFullHouse=: 3 : 0
if. 2~:#$y do. y=. suitRank y end.
NB. 0 1 1 1-:/:~2=/\/:~1{y
2 3-:/:~;#&.>(1,2~:/\/:~rnk)<;.1 rnk=. 1{y
)
is4ok=: 3 : 0
if. 2~:#$y do. y=. suitRank y end.
1 4-:/:~;#&.>(1,2~:/\/:~rnk)<;.1 rnk=. 1{y
)
isStraightFlush=: 3 : 0
if. 2~:#$y do. y=. suitRank y end.
(isAnyFlush y)*.isAnyStraight y NB. Is straight and flush.
)
NB. suitRank=: |:@((4 13)&#:)
suitRank=: 3 : 0
NB.* suitRank: convert nums: 2 rows: suit, rank or 2 rows->nums 0-51.
if. 2=#$y do.
13#.|:y
else.
|:@((4 13)&#:)y
end.
)
NB.* initPokerVars: initialize poker variables from scratch.
initPokerVars=: 3 : 0
h5=: 5 AllCombos 52
h5=: h5{"1~/:"(1) 13|h5 NB. Order each hand by card rank.
6!:2 'whall=. (isNothing"1 h5),.(isPair"1 h5),.(is2Pair"1 h5),.(is3ok"1 h5),.(isOnlyStraight"1 h5),.(isOnlyFlush"1 h5),.(isFullHouse"1 h5),.(is4ok"1 h5),.isStraightFlush"1 h5'
HANDRANKS=: rankAllHands whall;<h5
HANDGV=: /:|:HANDRANKS
RH5=: HANDGV{h5 NB. 2598960 5-:$RH5 NB. Hands in rated order least to best.
CHORDH5=: RH5{a.
HANDRATED=: HANDGV{&.|:HANDRANKS NB. HANDRATED: 0{Major type #, 1{minor type #
assert. HANDRATED -: /:~&.|:HANDRANKS
HandTypes=: ('#';'Name'),(<"0 i.9),.'nothing';'pair';'2-pair';'3-of-a-kind';'straight';'flush';'full house';'4-of-a-kind';'straight flush'
equihand=. -.*./"(1) 0,2=/\|:HANDRATED
EQUIRANK=: +/\equihand
lens=. 2-~/\I. equihand,1
EQHANDRANK=: lens#I. equihand
'RH5';'HANDRANKS';'HANDGV';'CHORDH5';'HANDRATED';'EQUIRANK';'EQHANDRANK'
)
exp=: #^:_1
3 : 0 ''
if. fexist 'RH5I.DAT' do. getPokerVars ''
else. initPokerVars '' end.
)
Some Example Usage
egs=: 0 : 0
$HR=: |:0 2861#: HRi
2 2598960
+/htp=. 1,2~:/\0{HR NB. Hand-type partition
9
]nht=. ;$&.>htp<;.(1)1{HR NB. number of each hand type
1302540 1098240 123552 54912 10200 5108 3744 624 40
]npt=. ;($@~.)&.>htp<;.(1) 1{HR NB. number subtypes per hand type
1277 2860 858 858 10 1277 156 156 10
pcts=. 100*&.>1E_7 roundNums pht,.(+/\pht=. nht%+/nht),.|.+/\(|.nht)%+/nht
pcts=. pcts,.]&.>0.1 roundNums %pht
htstats=. HANDTYPE,.]&.>nht,.npt,.>pcts
tit=. 'Hand Type';'# Type';'# Sub-type';'% Type';'Cum. %';'Rev. Cum. %';'Type/Hands'
tots=. ('Total';]&.>+/>_3}."1}."1 htstats),3$<' - '
tit,htstats,tots
+--------------+-------+----------+--------+--------+-----------+----------+
|Hand Type |# Type |# Sub-type|% Type |Cum. % |Rev. Cum. %|Type/Hands|
+--------------+-------+----------+--------+--------+-----------+----------+
|nothing |1302540|1277 |50.11774|50.11774|100 |2 |
+--------------+-------+----------+--------+--------+-----------+----------+
|pair |1098240|2860 |42.2569 |92.37464|49.88226 |2.4 |
+--------------+-------+----------+--------+--------+-----------+----------+
|2-pair |123552 |858 |4.7539 |97.12854|7.62536 |21 |
+--------------+-------+----------+--------+--------+-----------+----------+
|3-of-a-kind |54912 |858 |2.11285 |99.24139|2.87146 |47.3 |
+--------------+-------+----------+--------+--------+-----------+----------+
|straight |10200 |10 |0.39246 |99.63385|0.75861 |254.8 |
+--------------+-------+----------+--------+--------+-----------+----------+
|flush |5108 |1277 |0.19654 |99.83039|0.36615 |508.8 |
+--------------+-------+----------+--------+--------+-----------+----------+
|full house |3744 |156 |0.14406 |99.97445|0.16961 |694.2 |
+--------------+-------+----------+--------+--------+-----------+----------+
|4-of-a-kind |624 |156 |0.02401 |99.99846|0.02555 |4165 |
+--------------+-------+----------+--------+--------+-----------+----------+
|straight flush|40 |10 |0.00154 |100 |0.00154 |64974 |
+--------------+-------+----------+--------+--------+-----------+----------+
|Total |2598960|7462 |100 | - | - | - |
+--------------+-------+----------+--------+--------+-----------+----------+
)
game.ijs
Here we handle the mechanics of running the game.
NB.* game.ijs: handle book-keeping etc. pertaining to entire game (set of games).
initializeGame=: 3 : 0
np=. y NB. Number of players
PMONEY=: np$100 NB. Players start with 100 each.
LIMS=: 10 3 NB. Max bet 10, 3-raise limit
NB. Play hand of 7-card stud.
DECK=: 52?52 NB. Shuffle deck
PCARDS=: (np,7)$a: NB. Players' cards for 7-stud
DOWNC=: (1) 0 1 _1}7$0 NB. 1=downcard
NCD=: 3 NB. Number of cards dealt
nd=. np,NCD NB. Initially deal 3 to each
DECK=: DECK}.~*/nd [ PCARDS=: (np,7){.nd$DECK{.~*/nd
PMONEY=: PMONEY-1 [ POT=: +/np$1 NB. Ante 1/player
showCards 3{."1 PCARDS
)
betUpdates=: 3 : 0
'bettor b0'=. y
if. _1=b0 do. LIVE=: (0) bettor}LIVE
else. plix=. bettor i.~(] # [: i. #) LIVE
POT=: POT+b0 [ BETS=: (b0+plix{BETS) plix}BETS
PMONEY=: (b0-~bettor{PMONEY) bettor}PMONEY
end.
)
finishRound=: 3 : 0
DISCARDS=: ,DISCARDS,(-.LIVE)#UpCards NCD
NB. PMONEY=: PMONEY-BETS NB. This won't work unless we change to LIVE=: i.np
PPARM=: LIVE#PPARM [ BETS=: 0$~np=. #PCARDS=: LIVE#PCARDS [ NCD=: >:NCD
LIVE=: #~LIVE
np
)
dealNextCard=: 3 : 0
'deal DECK'=: y split DECK
PCARDS=: (deal) NCD}&.|:PCARDS
NCD=: >:NCD
)
players4.ijs
Here we attempt to define betting strategies on a range from "tight" - a conservative player - to "loose" - a very aggressive player.
NB.* players4.ijs: v.4: implement per player parameters, including estimates
NB. of opponent looseness.
coclass 'poker'
coinsert 'base'
ownMinusExtEst=: (([: > 1 { ]) - (<<1 0) |:&> 0 { ])"1
NB.* allPossHands7: return all possible bases for 7-card-stud (5-card) hand
NB. for 3-7 cards.
allPossHands7=: 3 : 0"1
assert. (8>#y) *. 2<#y
+./pHD ~.,/rmEachOne^:2]y
)
best5CardHand=: 3 : 'HANDRATED{~>./RH5i i. 52#."1 /:~"1 ~.,/rmEachOne^:(5-~#y)]y'"1
updScaling=: 3 : '3 0.25*1<.y-~1,~>./HRSUMMARY'"1
updateEst=: 3 : '0.1 0.9+0.08 _0.08*y'"0
updateEstNeutral=: 3 : '0.25*-0.4 0.6+_0.02 0.02*y'"0 NB. Neutral is slightly weak...
updateAggression=: 3 : 0
vals2upd=. y{"1 &>OHEST;OPARM
updamt=. (updScaling |:vals2upd) * updateEst 0{"1 PPARM{.~#OHEST
vals2upd=. vals2upd+|:(0) y}updamt NB. Don't update the aggressor...
OHEST=: (0{vals2upd) y}&.|:OHEST
OPARM=: (1{vals2upd) y}&.|:OPARM
updamt
)
updateNeutral=: 3 : 0
vals2upd=. y{"1 &>OHEST;OPARM
updamt=. (updScaling |:vals2upd) * updateEstNeutral 0{"1 PPARM{.~#OHEST
vals2upd=. vals2upd+|:(0) y}updamt NB. Don't update the aggressor...
OHEST=: (0{vals2upd) y}&.|:OHEST
OPARM=: (1{vals2upd) y}&.|:OPARM
updamt
)
takenfrom=: 4 : '(!y)%!y-x'
onlyCombos=: [: (] #~ [: -. ([: #&> ~.&.>) ~: #&>) [: , [: { [ $ [: < [: i. ]
NB.EG 60=#3 onlyCombos 5 NB. Indexes of 5 things taken 3 at a time.
NB.EG ((2#i.3),&.>1 2 0 2 0 1) -: /:~2 onlyCombos 3
NB.* rmEachOne: remove one of each item from vec -> mat w/shape (#y)-0 1.
rmEachOne=: (< #&>~ [: <"1 [: -. [: idMat #)"1
NB.* pHD: Possible Hands' Distribution (faster than possHandDist)
pHD=: RH5&(([: # ]) = [: +/"1 e.)"1
NB.* rmFrom: remove items at index x from y
rmFrom=: 4 : 'y#~(0) x}1$~#y'
NB. PPARM: Player parameters: Bluff (0-never, 1-always): tendency to raise
NB. when not justified by hand; Bet Agression (0-never raise, 1-always raise).
'PPTIT PPARM'=: split <;._1&>TAB,&.><;._2 ] 0 : 0
Bluff Bet Agression
0.0 0.0
0.5 0.0
0.5 0.5
1 0.0
1 0.5
0.0 1
)
NB. PPARM: Player parameters: Loose (0-conservative, 1-loose): willingness
NB. to take long-shots; Adapability (0-never adapts, 1-instantly adapts):
NB. how quickly Loose parameter changes based on how opponents play.
'PPTIT PPARM'=: split <;._1&>TAB,&.><;._2 ] 0 : 0
Loose Adaptability
0.0 0.0
0.5 0.0
0.5 0.5
1 0.0
1 0.5
0.0 1
)
PPARM=: ".&>PPARM
NB. exploration2=. 0 : 0
NB.* initGame: initialize game parms for y players.
initGame=: 3 : 0
NB. OPARM: Opponents' parameters: Nth row is player N's guess about opponents'
NB. "Loose" parameters where column # is opponent's number.
OPARM=: 0.5$~2$y NB. Uninformative prior
PMONEY=: y$100 NB. Players start with 100 each.
LIMS=: 10 3 NB. Max bet 10, 3-raise limit
DOWNC=: (1) 0 1 _1}7$0 NB. 1=downcard
)
dealCards=: 3 : 0
'deal DECK'=: (y*np=. +/LIVE) split DECK
PCARDS=: ((deal$~np,y) (NCD+i.y)}&.|:])(LIVE&#)PCARDS
NCD=: NCD+y
)
NB. startHand7s: setup for hand of 7-card stud.
startHand7s=: 3 : 0
np=. y NB. # players
OHEST=: 0$~2$np NB. Opponents hand strength estimate: 0 before deal.
DECK=: 52?52 NB. Shuffle deck
DISCARDS=: '' NB. No discarded up cards yet.
PCARDS=: (np,7)$_1 NB. Players' cards for 7-stud
NCD=: 0 NB. Number of cards dealt to each player so far.
LIVE=: np$1 NB. Who's still playing
BETS=: np$1 NB. Ante 1/player
PMONEY=: PMONEY-BETS [ POT=: +/BETS
BETS=: np$0 NB. Fresh round of betting
dealCards 3 NB. Initially deal 3 to each
)
gatherStats0=: 3 : 0
'np ng'=. y
rr=. 0 2$a:
while. _1<ng=. <:ng do.
startHand7s np [ initGame np
'display eoest ownests'=. calcPossibleHands np
rr=. rr,eoest;<ownests
while. NCD<7 do. dealNextCard np
'display eoest ownests'=. calcPossibleHands np
rr=. rr,eoest;<ownests
end.
rr=. rr,1;PCARDS
end.
)
exploration2=. 0 : 0
initGame np=. 5
startHand7s np
'display eoest ownests'=. calcPossibleHands np
]opener=. bettor=. best1Card UpCards NCD
0
bettor{PPARM
0 0
display
+---+--+---+-------+-----------------------------+-----------+
|H1 |H2|Up1|OwnPoss|AdjustedEachOtherEst |EachRanking|
+---+--+---+-------+-----------------------------+-----------+
|10C|AC|AS |2.298 |1.853 1.558 1.531 1.501 1.454|4 3 2 1 0 |
+---+--+---+-------+-----------------------------+-----------+
|2C |JS|8D |0.837 |1.273 0.967 0.964 1.03 0.888 |4 2 1 3 0 |
+---+--+---+-------+-----------------------------+-----------+
|KH |8S|7C |0.972 |1.349 0.964 1.032 1.104 0.962|4 1 2 3 0 |
+---+--+---+-------+-----------------------------+-----------+
|9H |2D|10D|0.821 |1.262 0.966 0.948 0.991 0.871|4 2 1 3 0 |
+---+--+---+-------+-----------------------------+-----------+
|JH |AD|3C |1.131 |1.368 1.157 1.139 1.2 1.075 |4 2 1 3 0 |
+---+--+---+-------+-----------------------------+-----------+
POT
5
NPB=: 1 5 5 5 8 10 10 NB. Normal Betting Pattern? (to judge if bet high or low).
DONTSCAREM=: 0.2 NB. Bettor's hand too good to force people out this early...
]b0=. roundNums 0.5+DONTSCAREM*(hiddenStrength+0{bettor{PPARM)*POT<.0{LIMS
3
betUpdates bettor,b0
96 99 99 99 99
POT;BETS;PMONEY;LIVE
+-+---------+--------------+---------+
|8|3 0 0 0 0|96 99 99 99 99|1 1 1 1 1|
+-+---------+--------------+---------+
OO=. OHEST;<OPARM
updateAggression 0 NB. Everyone revises opinion on hand strength and player looseness...
0.3 0.1125
0.42 0.1075
0.42 0.1075
0.54 0.1025
0.54 0.1025
OO,:OHEST;OPARM
+-----------------------------+----------------------+
|1.408 1.113 1.086 1.056 1.009|0.5 0.5 0.5 0.5 0.5 |
|1.404 1.098 1.095 1.161 1.019|0.5 0.5 0.5 0.5 0.5 |
| 1.41 1.025 1.093 1.165 1.023|0.5 0.5 0.5 0.5 0.5 |
|1.433 1.137 1.119 1.162 1.042|0.5 0.5 0.5 0.5 0.5 |
|1.311 1.1 1.082 1.143 1.018|0.5 0.5 0.5 0.5 0.5 |
+-----------------------------+----------------------+
|1.408 1.113 1.086 1.056 1.009| 0.5 0.5 0.5 0.5 0.5|
|1.824 1.098 1.095 1.161 1.019|0.6075 0.5 0.5 0.5 0.5|
| 1.83 1.025 1.093 1.165 1.023|0.6075 0.5 0.5 0.5 0.5|
|1.973 1.137 1.119 1.162 1.042|0.6025 0.5 0.5 0.5 0.5|
|1.851 1.1 1.082 1.143 1.018|0.6025 0.5 0.5 0.5 0.5|
+-----------------------------+----------------------+
]bettor=. bettor+1 i.~LIVE|.>:bettor
1
bettor{PPARM
0.5 0
]hiddenStrength=. ^(bettor{ownests)-(<2$bettor){OHEST
0.77018076
ownests
2.2983039 0.83686996 0.97154052 0.82097108 1.1311721
roundNums (0{bettor{PPARM)*POT<.0{LIMS
4
b0=. 3 NB. Call
betUpdates bettor,b0
POT;BETS;PMONEY;LIVE
+--+---------+--------------+---------+
|15|0 0 0 5 5|99 99 99 94 94|0 1 2 3 4|
+--+---------+--------------+---------+
updateNeutral bettor
_0.3 _0.01875
_0.2925 _0.0190625
_0.2925 _0.0190625
_0.285 _0.019375
_0.285 _0.019375
OO,:OHEST;OPARM
+------------------------------+----------------------------+
|1.408 1.113 1.086 1.056 1.009 |0.5 0.5 0.5 0.5 0.5 |
|1.404 1.098 1.095 1.161 1.019 |0.5 0.5 0.5 0.5 0.5 |
| 1.41 1.025 1.093 1.165 1.023 |0.5 0.5 0.5 0.5 0.5 |
|1.433 1.137 1.119 1.162 1.042 |0.5 0.5 0.5 0.5 0.5 |
|1.311 1.1 1.082 1.143 1.018 |0.5 0.5 0.5 0.5 0.5 |
+------------------------------+----------------------------+
|1.408 0.813 1.086 1.056 1.009| 0.5 0.48125 0.5 0.5 0.5|
|1.824 1.098 1.095 1.161 1.019|0.6075 0.5 0.5 0.5 0.5|
| 1.83 0.7325 1.093 1.165 1.023|0.6075 0.4809375 0.5 0.5 0.5|
|1.973 0.852 1.119 1.162 1.042|0.6025 0.480625 0.5 0.5 0.5|
|1.851 0.815 1.082 1.143 1.018|0.6025 0.480625 0.5 0.5 0.5|
+------------------------------+----------------------------+
]bettor=. bettor+1 i.~LIVE|.>:bettor
2
b0=. 3 NB. Just call...
bettor{PPARM
0.5 0.5
updateNeutral bettor
_0.3 _0.01875
_0.2925 _0.0190625
_0.2925 _0.0190625
_0.285 _0.019375
_0.285 _0.019375
OHEST;OPARM
+-------------------------------+----------------------------------+
|1.408 0.813 0.786 1.056 1.009| 0.5 0.48125 0.48125 0.5 0.5|
|1.824 1.098 0.8025 1.161 1.019|0.6075 0.5 0.4809375 0.5 0.5|
| 1.83 0.7325 1.093 1.165 1.023|0.6075 0.4809375 0.5 0.5 0.5|
|1.973 0.852 0.834 1.162 1.042|0.6025 0.480625 0.480625 0.5 0.5|
|1.851 0.815 0.797 1.143 1.018|0.6025 0.480625 0.480625 0.5 0.5|
+-------------------------------+----------------------------------+
]bettor=. bettor+1 i.~LIVE|.>:bettor
3
bettor{PPARM
1 0
]hiddenStrength=. ^(bettor{ownests)-(<2$bettor){OHEST
0.71103834
roundNums (0{LIMS)<.(0{bettor{PPARM)*(>./BETS)
3
roundNums (0{LIMS)<.hiddenStrength+(0{bettor{PPARM)*>./BETS
4
display
+---+--+---+-------+-----------------------------+-----------+
|H1 |H2|Up1|OwnPoss|AdjustedEachOtherEst |EachRanking|
+---+--+---+-------+-----------------------------+-----------+
|10C|AC|AS |2.298 |1.853 1.558 1.531 1.501 1.454|4 3 2 1 0 |
+---+--+---+-------+-----------------------------+-----------+
|2C |JS|8D |0.837 |1.273 0.967 0.964 1.03 0.888 |4 2 1 3 0 |
+---+--+---+-------+-----------------------------+-----------+
|KH |8S|7C |0.972 |1.349 0.964 1.032 1.104 0.962|4 1 2 3 0 |
+---+--+---+-------+-----------------------------+-----------+
|9H |2D|10D|0.821 |1.262 0.966 0.948 0.991 0.871|4 2 1 3 0 |
+---+--+---+-------+-----------------------------+-----------+
|JH |AD|3C |1.131 |1.368 1.157 1.139 1.2 1.075 |4 2 1 3 0 |
+---+--+---+-------+-----------------------------+-----------+
b0=. 3
betUpdates bettor,b0
96 96 96 96 99
updateNeutral bettor
_0.3 _0.01875
_0.2925 _0.0190625
_0.2925 _0.0190625
_0.285 _0.019375
_0.285 _0.019375
(bettor{PPARM);bettor=. bettor+1 i.~LIVE|.>:bettor
+-----+-+
|1 0.5|4|
+-----+-+
]hiddenStrength=. ^(bettor{ownests)-(<2$bettor){OHEST
1.1198247
roundNums (0{LIMS)<.hiddenStrength+(0{bettor{PPARM)*>./BETS
4
POT%4
4.25
NB. Probably should raise but let's get to next card...
b0=. 3
betUpdates bettor,b0
96 96 96 96 96
updateNeutral bettor
_0.3 _0.01875
_0.2925 _0.0190625
_0.2925 _0.0190625
_0.285 _0.019375
_0.285 _0.019375
(bettor{PPARM);bettor=. bettor+1 i.~LIVE|.>:bettor
+---+-+
|0 1|5|
+---+-+
opener=bettor
0
({.*./ . =}.) BETS
1
if. (opener = bettor=. LIVE{~(#LIVE)|>:LIVE i. bettor) *. (] *./ .= {.) LIVE{BETS do.
NB. This round is done. Do cleanup: remove folded players, keep track of
NB. their discards.
DISCARDS=: DISCARDS,,(LIVE-.~i.np){UpCards NCD
PPARM=: LIVE{PPARM [ BETS=: 0$~np=. #PCARDS=: LIVE{PCARDS [ NCD=: >:NCD
end.
display
+---+--+---+---+-------+-----------------------+-----------+
|H1 |H2|Up1|Up2|OwnPoss|AdjustedEachOtherEst |EachRanking|
+---+--+---+---+-------+-----------------------+-----------+
|10D|KC|4S |6H |0.805 |0.899 0.815 0.929 1.213|1 0 2 3 |
+---+--+---+---+-------+-----------------------+-----------+
|4H |2H|3H |5S |0.943 |0.983 0.923 1.095 1.353|1 0 2 3 |
+---+--+---+---+-------+-----------------------+-----------+
|3C |JS|9C |5C |0.555 |0.78 0.628 0.792 1.088 |1 0 2 3 |
+---+--+---+---+-------+-----------------------+-----------+
|3S |KH|8D |AS |1.11 |0.909 0.756 0.955 1.206|1 0 2 3 |
+---+--+---+---+-------+-----------------------+-----------+
opener=. bettor=. best2Card UpCards NCD
3
bettor{PPARM
1 0.5
]b0=. roundNums (0{bettor{PPARM)*POT<.0{LIMS
10
betUpdates bettor,b0
94 99 94 94 84
POT;BETS;PMONEY;LIVE
+--+--------+--------------+-------+
|35|0 0 0 10|94 99 94 94 84|0 2 3 4|
+--+--------+--------------+-------+
]bettor=. (#LIVE)|>:bettor
0
bettor{PPARM
0 0
roundNums (0{bettor{PPARM)*POT<.0{LIMS
0
b0=. _1 NB. Folds
]bettor=. (#LIVE)|>:bettor
1
bettor{PPARM
0.5 0.5
roundNums (0{bettor{PPARM)*POT<.0{LIMS
5
BETS
0 0 0 10
>./BETS
10
POT
35
b0=. 10 NB. Adjust formula so this happens...
NB. Perhaps magnitude of disparity between diagonal and ownests -> a signal?
NB. Also, last player should notice other 2 called his king showing: how
NB. to represent this knowledge? He needs to have a sense how loose each
NB. is to estimate if their hole cards beat his king, also based on their
NB. bets.
]hiddenStrength=. ^(bettor{ownests)-(<2$bettor){eoest
1.0392541
]b0=. roundNums (hiddenStrength+0{bettor{PPARM)*POT<.0{LIMS
15 NB. Raise 5?
betUpdates bettor,b0
94 99 94 79 84
POT;BETS;PMONEY;LIVE
+--+---------+--------------+-----+
|50|0 15 0 10|94 99 94 79 84|2 3 4|
+--+---------+--------------+-----+
oix=. bettor{LIVE
NB. Haven't quite figured this out...
oix=. 2
]OHEST=: (-:1+oix{"1 OHEST) oix}&.|:OHEST
0 0 0.5 0 0
0 0 0.5 0 0
0 0 0.5 0 0
0 0 0.5 0 0
0 0 0.5 0 0
bettor{PPARM
1 0
]hiddenStrength=. ^(bettor{ownests)-(<2$bettor){eoest
0.62314395
]b0=. roundNums (hiddenStrength+0{bettor{PPARM)*POT<.0{LIMS
16
BETS
0 15 0 10
>./BETS
15
(bettor{ownests)-(<2$bettor){eoest
_0.47297772
betUpdates bettor,b0
94 99 94 79 68
POT;BETS;PMONEY;LIVE
+--+----------+--------------+-----+
|66|0 15 16 10|94 99 94 79 68|2 3 4|
+--+----------+--------------+-----+
oix=. 3
]OHEST=: (-:1+oix{"1 OHEST) oix}&.|:OHEST
0 0 0.5 0.5 0
0 0 0.5 0.5 0
0 0 0.5 0.5 0
0 0 0.5 0.5 0
0 0 0.5 0.5 0
bettor=. 3
bettor{PPARM
1 0.5
b0=. 6 NB. Just call...
betUpdates bettor,b0
POT;BETS;PMONEY;LIVE
+--+----------+--------------+-----+
|72|0 15 16 16|94 99 79 78 78|2 3 4|
+--+----------+--------------+-----+
betUpdates 1 1
POT;BETS;PMONEY;LIVE
+--+-----+--------------+-----+
|73|1 0 0|94 99 78 78 78|2 3 4|
+--+-----+--------------+-----+
if. (opener = bettor=. LIVE{~(#LIVE)|>:LIVE i. bettor) *. (] *./ .= {.) LIVE{BETS do.
NB. This round is done. Do cleanup: remove folded players, keep track of
NB. their discards.
DISCARDS=: DISCARDS,,0{UpCards NCD
PPARM=: _3{.PPARM [ BETS=: 0$~np=. #PCARDS=: _3{.PCARDS [ NCD=: >:NCD
end.
np=. finishRound ''
]PCARDS=: dealNextCard np
28 26 27 42 35 0 0
1 48 7 3 9 0 0
40 37 19 51 6 0 0
'display eoest ownests'=. calcPossibleHands np
display
+--+--+---+---+---+-------+--------------------+-----------+
|H1|H2|Up1|Up2|Up3|OwnPoss|AdjustedEachOtherEst|EachRanking|
+--+--+---+---+---+-------+--------------------+-----------+
|4H|2H|3H |5S |JH |0.096 |0.431 0.794 1.589 |0 1 2 |
+--+--+---+---+---+-------+--------------------+-----------+
|3C|JS|9C |5C |JC |1.706 |0.993 1.389 2.242 |0 1 2 |
+--+--+---+---+---+-------+--------------------+-----------+
|3S|KH|8D |AS |8C |1.535 |0.55 0.93 1.721 |0 1 2 |
+--+--+---+---+---+-------+--------------------+-----------+
NB. player 0 here has gotten much worse even w/4-flush?
PPARM{~opener=. bettor=. best3Card UpCards NCD
0 1
]b0=. roundNums (0{LIMS)<.(hiddenStrength+0{bettor{PPARM)*POT<.0{LIMS
10 NB. Loose bet...
betUpdates bettor,b0
94 99 68 78 68
POT;BETS;PMONEY;LIVE
+--+-------+--------------+-----+
|93|10 0 10|94 99 68 78 68|2 3 4|
+--+-------+--------------+-----+
]bettor=. (#LIVE)|>:bettor
1
bettor{PPARM
1 0
]hiddenStrength=. ^(bettor{ownests)-(<2$bettor){eoest
1.8831499
roundNums (hiddenStrength+0{bettor{PPARM)*POT<.0{LIMS
29
b0=. 15 NB. Raise 5...
betUpdates bettor,b0
94 99 68 63 68
POT;BETS;PMONEY;LIVE
+---+--------+--------------+-----+
|108|10 15 10|94 99 68 63 68|2 3 4|
+---+--------+--------------+-----+
]bettor=. (#LIVE)|>:bettor
2
betUpdates bettor,5 NB. Call
94 99 68 63 63
]bettor=. (#LIVE)|>:bettor
0
]hiddenStrength=. ^(bettor{ownests)-(<2$bettor){eoest
0.51094882
roundNums (hiddenStrength+0{bettor{PPARM)*POT<.0{LIMS
10
>./BETS
15
betUpdates bettor,5 NB. Loose call
94 99 63 63 63
POT;BETS;PMONEY;LIVE
+---+--------+--------------+-----+
|118|15 15 15|94 99 63 63 63|2 3 4|
+---+--------+--------------+-----+
NB. finishRound - need to improve this logic
DISCARDS=: ,DISCARDS,''
LIVE
2 3 4
BETS=: 0$~np=. #PCARDS
BETS
0 0 0
NCD=: >:NCD
PCARDS=: dealNextCard np
'display eoest ownests'=. calcPossibleHands np
display
+--+--+---+---+---+---+-------+--------------------+-----------+
|H1|H2|Up1|Up2|Up3|Up4|OwnPoss|AdjustedEachOtherEst|EachRanking|
+--+--+---+---+---+---+-------+--------------------+-----------+
|4H|2H|3H |5S |JH |AC |0 |0.479 0.963 1.211 |0 1 2 |
+--+--+---+---+---+---+-------+--------------------+-----------+
|3C|JS|9C |5C |JC |6C |0 |0.245 0.684 1.006 |0 1 2 |
+--+--+---+---+---+---+-------+--------------------+-----------+
|3S|KH|8D |AS |8C |6D |0 |0.113 0.59 0.84 |0 1 2 |
+--+--+---+---+---+---+-------+--------------------+-----------+
NB. An obvious winner but let's just deal the last hole card to check calcPossibleHands...
)
upcardPossibleHand=: 3 : 0
'xclmine ix'=. y
uphand=. ix{(NCD{.-.DOWNC)#"1 NCD{."1 PCARDS
(xclmine+.(|:RH5)+./ . e. uphand) *. possHandDist uphand
)
NB.EG othPoss=. upcardPossibleHand &> (<xclupmine);&.>bettor -.~ i.np
NB.EG mean &> (<"1 othPoss)#&.><0{"1 HANDRATED
UpCards=: 3 : '(y{.-.DOWNC)#"1 y{."1 PCARDS'"0 NB. y=NCD
NB.* myPossHandXclUps: my hand possibilities, accounting for up cards.
myPossHandXclUps=: (3 : 0)"0
upcards=. UpCards NCD [ myhand=. NCD{.y{PCARDS
(-.(|:RH5)+./ . e. (DISCARDS,,upcards) -. myhand) *. allPossHands7 myhand
)
NB.* theirPossHands: each other players' possibility based on their up card and my hole cards and all other up cards.
theirPossHands=: (3 : 0)"0
upcards=. UpCards NCD [ myhand=. NCD{.y{PCARDS
xclcards=. ~.&.>(<myhand,,upcards,DISCARDS)-.&.>(<myhand) y}<"1 upcards
(-.(<|:RH5)+./ .e. &> xclcards) *. pHD"1 upcards
)
NB.EG mean &> (<"1 theirPossHands 0) #&.> <HRSUMMARY
calcPossibleHands=: 3 : 0
np=. y
allupposs=. theirPossHands i. np
eoest=. (13 : '0.001 roundNums (+/"1 y)%~y+/ . *HRSUMMARY') allupposs NB. Each others' estimates
ownests=. (13 : '(+/"1 y)%~HRSUMMARY+/ . *|:y') myPossHandXclUps i.np
ss0=. (showCards NCD{."1 PCARDS),.<"0 ] 0.001 roundNums ownests
tit=. ('H',&.>":&.>>:i.+/NCD{.DOWNC),(<'Up'),&.>":&.>>:i.+/-.NCD{.DOWNC
if. 7=#tit do. tit=. tit{~/:(I. DOWNC),I.-.DOWNC end.
tit=. tit,'OwnPoss';'AdjustedEachOtherEst';'EachRanking'
NB. Adjust by half of own adjustment - this adjustment doesn't make too much sense.
display=. tit,ss0,.(<"1]0.001 roundNums eoest+"(1 0) -:ownests-(<0 1)|:eoest),.<"1 /:"1 ] 0.001 roundNums eoest+"(1 0) ownests-(<0 1)|:eoest
display;eoest;ownests
NB.EG 'display eoest ownests'=. calcPossibleHands np
)
NB.* allPossHands: hand possibilities for player #y, accounting for up cards.
allPossHands=: (3 : 0)"0
upcards=. UpCards NCD [ myhand=. NCD{.y{PCARDS
(+./pHD&>(<myhand){~&.>(NCD-2) onlyCombos NCD) *. -.+./"1 RH5 e. ,(<<<y){upcards
)
NB.* theirPHs: hand possibilities players other than y, accounting for all up and his down cards.
theirPHs=: (3 : 0)"0
upcards=. UpCards NCD [ myhand=. NCD{.y{PCARDS
xclcards=. ~.&.>(<myhand,,upcards,DISCARDS)-.&.>(<myhand) y}<"1 upcards
mean&>((+./&.>pHD&.><"1 upcards) *.&.> -.&.>woCards &.> xclcards)#&.><HRSUMMARY
)
calcPH=: 3 : 0
np=. y
eoest=. theirPHs i.np NB. Each others' estimates
ownests=. (HRSUMMARY&(([: +/"1 ]) %~ [ +/ .* [: |: ])) allPossHands i.np
ss0=. (showCards NCD{."1 PCARDS),.<"0 ] 0.001 roundNums ownests
tit=. ('H',&.>":&.>>:i.+/NCD{.DOWNC),(<'Up'),&.>":&.>>:i.+/-.NCD{.DOWNC
tit=. tit,'OwnPoss';'AdjustedEachOtherEst';'EachRanking'
NB. Adjust by half of own adjustment - this adjustment doesn't make too much sense.
display=. tit,ss0,.(<"1]0.001 roundNums eoest+"(1 0) -:ownests-(<0 1)|:eoest),.<"1 /:"1 ] 0.001 roundNums eoest+"(1 0) ownests-(<0 1)|:eoest
display;eoest;ownests
NB.EG 'display eoest ownests'=. calcPH np
)
myEstAdvantage=: ([: <./ { % ] {~ [: < [: < [: < [)
NB.EG bettor myEstAdvantage bettor{eoestroundNums (hiddenStrength+0{bettor{PPARM)*POT<.0{LIMS
coclass 'base'
Advanced Topics
Here we consider how large a programming language is, and by what measure, as well as some of the implications of a language's size.
The Size of J
from Devon McCormick devonmcc@gmail.com to programming@jsoftware.com, J-Programming@googlegroups.com date Thu, Aug 4, 2011 at 11:13 AM subject The size of J
Hi -
I was reading a section in "Patterns of Software" by Richard P. Gabriel in which he talks about "language size". This book is one of those annoying ones in which he seems to argue for many of the strengths of an APL but never, based on the parts I've read, mentions APL (though he must have known of it).
In the essay on "Language Size", he talks about how the initial implementation of Common Lisp "...was relatively small: 772 defined symbols, including function names, macro names, global variables, and constants." Much of this essay builds the case for a small (but not too small) language being better than a large one. He also touches on the usefulness of arrays, in a way.
In any case, here's my count for the size of J7:
Vocabulary page: (*/10 4 3)-6 Foreign#: 0 1 2 3 4 5 6 7 8 9 11 13 15 18 128 Foreigns: +/3 20 7 7 6 7 11 5 3 42 1 21 5 7 6 Total: +/114 151 NB. Basic vocabulary symbols + foreigns. +/114 114 151 NB. monads and dyads - assumes all have both forms, but... 379 _24 NB. not both monadic and dyadic - above letters on Vocabulary page... _22 NB. not both - letters and numerals NB. Total: +/114 114 151 _24 _22 NB. monads and dyads and foreigns - univalents 333
So, 333 semantic tokens in total, by my count.
A Response from Roger
from Roger Hui rhui000@shaw.ca via srs.acm.org reply-to Programming forum <programming@jsoftware.com> date Thu, Aug 4, 2011 at 12:53 PM subject Re: [Jprogramming] The size of J
I think you have to do this kind of count (and comparisons of counts) with care. For example, do you count + as one or two? Do you count o. as one or two or 27 (i:12 plus 1 for the monad)?
Also, f/ provides two families of functions. etc. etc.
Based on Roger's comments:
+/333 23 NB. (>:#i:12 o. fns - 2 already counted) 356
Adding in my own thoughts about number types:
nn=. (3 : 0)"0 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' try. ".'1',y,'1' catch. return. [ rr=. a: end. <y ) $(,nn)-.a: 9 (,nn)-.a: +-+-+-+-+-+-+-+-+-+ |b|d|e|j|p|r|x|D|E| +-+-+-+-+-+-+-+-+-+ +/356 9 NB. Any others? 365
Elucidation of Counts
from Devon McCormick devonmcc@gmail.com date Thu, Aug 4, 2011 at 1:22 PM
I counted "+" and "o." both as two because both have monadic and dyadic forms. Perhaps I should count "o." as 26 (= >:#i:12), though I'm inclined to stick with 2 because the dyadic form covers a closely-related group. I also ignored the many different kinds of numbers though I probably should include them as they are distinct uses of some of the letters.
Even with generous inclusions, I doubt we're pushing 400.
There was this suggestion from Henry:
from Henry Rich HenryHRich@nc.rr.com via srs.acm.org date Thu, Aug 4, 2011 at 1:28 PM
You said the Lisp analysis was of the implementation, not the language. So maybe you should be looking at the source for the J interpreter.
However,
from Devon McCormick devonmcc@gmail.com date Thu, Aug 4, 2011 at 1:44 PM
The statement was "772 defined symbols" which sounds like an external, language-oriented view. He also mentions that "ANSI Common Lisp has about 1,000 defined symbols and its specification is 1,300 pages long" though I see he's calling this a large language and he himself is really arguing _against_ small languages by attempting to refute arguments (mostly from "John David Stone") in their favor. Part of his argument is about blurring the line between a language proper and its libraries.
Another way he gives to measure the size of a language is by how long it takes to master it. By this standard, J is gargantuan. However, this is a flawed measure; a good essay on this is Peter Norvig's "Teach Yourself Programming in Ten Years": http://norvig.com/21-days.html .
Another Count
From Murray Eisenberg murray@math.umass.edu via srs.acm.org reply-to Programming forum <programming@jsoftware.com> date Thu, Aug 4, 2011 at 5:33 PM subject Re: [Jprogramming] Programming Digest, Vol 71, Issue 7
Some years ago at a J conference I gave a talk comparing J with Mathematica. One of the things I considered was the number of built-in objects.
One of the points I made, which really riled Ken Iverson, was that (at that time) the number of such objects was not really all that different between Mathematica and J. And to arrive at that conclusion, I counted the objects in quite a different way from what you did.
Two of my points were:
(1) The verb "o." should _not_ be counted as just one such object. Rather, it should be counted as around 24 separate objects. After all, you have to pair the verb with a left argument, and each left argument provides a different "function" in the mathematical sense. It is no more correct to claim that "1 & o." and "2 & o." are just special cases of the same creature as it would be to claim that Mathematica's Sin and Cos are special cases of the same creature. In particular, you still need to remember in the case of J that the left argument 1 provides the sine function and 2 the cosine function -- which is no more (human) memory taxing that to remember that Sin is the sine function whereas Cos is the cosine function: the names of the underlying entities with Mathematica just differ in the prefix "co".
(2) Each J verb (and other parts of speech) that has both a monadic and a dyadic use should be counted as (at least) two separate objects, despite being represented by a single symbol. For example "<." is Floor when used monadically but Lesser Of when used dyadically; and these two underlying functions, however closely related they may be, are nonetheless different functions.
By my count at that time, the numbers of primitives in the two languages were of the same order of magnitude, or even closer.
(Today, the situation would be different, though: as each successive version of Mathematica is released, more and more functions that used to be in standard add-on packages are now available directly in the kernel.)
In any case, counting such objects is at best a truly first-order approximation to the complexity of a programming language -- for the user. Especially for novices, what may matter a whole lot more is how similar function names or symbols are to mathematical or other terms they already know. In the same way that it may be easier to learn French if you know another Romance language (or Latin) than to learn Russian.
Learning, Teaching and Promoting J
Here we look at some possible topics by which to introduce J to a meeting of functional programmers.
Map-Reduce Redux
As the joke goes, Google invented map-reduce in 2004 and Ken Iverson cleverly re-invented it in 1966.
The following is from Wikipedia in 2011; however, the MapReduce page has changed considerably since this was copied from there.
MapReduce
MapReduce is a patented[1] software framework introduced by Google in 2004 to support distributed computing on large data sets on clusters of computers.[2] The framework is inspired by the map and reduce functions commonly used in functional programming,[3] although their purpose in the MapReduce framework is not the same as their original forms.[4] MapReduce libraries have been written in C++, C#, Erlang, Java, OCaml, Perl, Python, PHP, Ruby, F#, R and other programming languages.
Map (higher-order function)
In many programming languages, map is the name of a higher-order function that applies a given function to each element of a list, returning a list of results. They are examples of both catamorphisms and anamorphisms. This is often called apply-to-all when considered a functional form.
For example, if we define a function square as follows:
square x = x * x
Then calling map square [1,2,3,4,5] will return [1,4,9,16,25], as map will go through the list, and apply the function square to each element.
Fold (higher-order function)
In functional programming, fold, also known variously as reduce, accumulate, compress, or inject, is a family of higher-order functions that iterate an arbitrary function over a data structure in some order and build up a return value. Typically, a fold deals with two things: a combining function and a list of elements of some data structure. The fold then proceeds to combine elements of the data structure using the function in some systematic way.
Folds are in a sense dual to unfolds, which take a starting value of some other type and apply a function recursively to decide how to construct a data structure, whereas a fold recursively breaks that structure down, replacing it with other functions and values (anamorphism as opposed to catamorphism).
Folds on lists
The folding of the list [1,2,3,4,5] with the addition operator would result in 15, the sum of the elements of the list [1,2,3,4,5]. To a rough approximation, one can think of this fold as replacing the commas in the list with the + operation, giving 1 + 2 + 3 + 4 + 5.
In the example above, + is an associative operation, so the final result will be the same regardless of parenthesization, although the specific way in which it is calculated will be different. In the general case of non-associative binary functions, the order in which the elements are combined may influence the final result's value. On lists, there are two obvious ways to carry this out: either by combining the first element with the results of recursively combining the rest (called a right fold) or by combining the results of recursively combining all but the last element, with the last one (called a left fold). With a right fold, the sum would be parenthesized as 1 + (2 + (3 + (4 + 5))), whereas with a left fold it would be parenthesized as (((1 + 2) + 3) + 4) + 5.
In practice, it is convenient and natural to have an initial value which in the case of a right fold is used when one reaches the end of the list, and in the case of a left fold is what is initially combined with the first element of the list. In the example above, the value 0 (the additive identity) would be chosen as an initial value, giving 1 + (2 + (3 + (4 + (5 + 0)))) for the right fold, and ((((0 + 1) + 2) + 3) + 4) + 5 for the left fold.
Linear vs. tree-like folds
The use of initial value is mandatory when the combining function is asymmetrical in its types, i.e. when the type of its result is different from the type of list's elements. Then an initial value must be used, with the same type as that of the function's result, for a linear chain of applications to be possible, whether left- or right-oriented.
When the function is symmetrical in its types the parentheses may be placed in arbitrary fashion thus creating a tree of nested sub-expressions, e.g. ((1 + 2) + (3 + 4)) + 5. If the binary operation is associative this value will be well-defined, i.e. same for any parenthesization, although the operational details of how it is calculated will be different.
List folds as structural transformations
[Much of the following can still be found on Wikipedia ]
Folds can be viewed as a mechanism for replacing the structural components of a data structure with functions and values in a regular way. In many languages, lists are built up from two primitives: any list is either the empty list, commonly called nil ([] in Haskell), or it is a list constructed by appending an element to the start of some other list, which is called a cons (X1:(...:(Xn:nil)) or cons(X1,cons(X2,cons(...(cons(Xn,nil))))).
| The empty list and the cons operation are written as [] and (:) (colon) in Haskell. One can view a right fold as substituting the nil at the end of the list with a specific value, and each cons with a specific other function. Hence, one gets a diagram which looks something like this: | 
|
| In the case of a left fold, the structural transformation being performed is somewhat less natural, but is still quite regular:
These pictures illustrate the names left and right fold visually. They also highlight the fact that foldr (:) [] is the identity function (a shallow copy in Lisp parlance) on lists, as replacing cons with cons and nil with nil will not change the result. The left fold diagram suggests an easy way to reverse a list, foldl (flip (:)) []. |

|
Note that the parameters to cons must be flipped, because the element to add is now the right hand parameter of the combining function. Another easy result to see from this vantage-point is to write the higher-order map function in terms of foldr, by composing the function to act on the elements with cons, as:
map f = foldr ((:) . f) []
where the period (.) is an operator denoting function composition. This way of looking at things provides a simple route to designing fold-like functions on other algebraic data structures, like various sorts of trees. One writes a function which recursively replaces the constructors of the datatype with provided functions, and any constant values of the type with provided values. Such a function is generally referred to as a catamorphism.
Implementation
Linear Folds
Using Haskell as an example, foldl and foldr can be formulated in a few equations.
foldl f z [] = z foldl f z (x:xs) = foldl f (f z x) xs
If the list is empty, the result is the initial value. If not, fold the tail of the list using as new initial value the result of applying f to the old initial value and the first element.
foldr f z [] = z foldr f z (x:xs) = f x (foldr f z xs)
If the list is empty, the result is the initial value z. If not, apply f to the first element and the result of folding the rest.
Tree-like folds
Lists can be folded over in a tree-like fashion, both for finite and for indefinitely defined lists:
foldt f z [] = z foldt f z [x] = x foldt f z xs = foldt f z (pairs f xs) foldi f z [] = z foldi f z (x:xs) = f x (foldi f z (pairs f xs)) pairs f (x:y:t) = f x y : pairs f t pairs f t = t
In the case of foldi function to avoid its runaway evaluation on indefinitely defined lists the function f must not always demand its second argument's value, at least not all of it, and/or not immediately (example below).
Comparison of Fold and Map in Various Languages
[This pre-dates more generalized fold and map introduced into J in 2020. A much more extensive version of this table is now available; In the version below, we added the line for APL now present in the contemporary version of this table. ]
| Language | Left fold | Right fold | Left fold without initial value | Right fold without initial value |
|---|---|---|---|---|
| APL | func⍨/⌽initval,vector | func/vector,initval | func⍨/⌽vector | func/vector |
| Common Lisp | (reduce func list :initial-value initval) | (reduce func list :from-end t :initial-value initval) | (reduce func list) | (reduce func list :from-end t) |
| F# | Seq/List.fold func initval list | List.foldBack func list initval | Seq/List.reduce func list | List.reduceBack func list |
| Groovy | list.inject(initval, func) | list.reverse().inject(initval, func) | list[1..-1].inject(list[0], func) | list[-2..0].inject(list[-1], func) |
| Haskell | foldl func initval list | foldr func initval list | foldl1 func list | foldr1 func list |
| J | verb~/|. initval,array | verb/ array,initval | verb~/|. array | verb/ array |
| OCaml | List.fold_left func initval list | List.fold_right func list initval | ||
| Array.fold_left func initval array | Array.fold_right func array initval | |||
| Scala | list.foldLeft(initval)(func) | list.foldRight(initval)(func) | list.reduceLeft(func) | list.reduceRight(func) |
Evaluation Order Considerations
In the presence of lazy, or normal-order evaluation, foldr will immediately return the application of f to the head of the list and the recursive case of folding over the rest of the list. Thus, if f is able to produce some part of its result without reference to the recursive case on its "right" i.e. in its second argument, and the rest of the result is never demanded, then the recursion will stop (e.g. head == foldr (\a b->a) undefined). This allows right folds to operate on infinite lists. By contrast, foldl will immediately call itself with new parameters until it reaches the end of the list. This tail recursion can be efficiently compiled as a loop, but can't deal with infinite lists at all — it will recurse forever in an infinite loop.
Having reached the end of the list, an expression is in effect built by foldl of nested left-deepening f-applications, which is then presented to the caller to be evaluated. Were the function f to refer to its second argument first here, and be able to produce some part of its result without reference to the recursive case (here, on its "left" i.e. in its first argument), then the recursion would stop. This means that while foldr recurses "on the right" it allows for the combining function to inspect the list's elements from the left; and conversely, while foldl recurses "on the left" it allows for the combining function to inspect the list's elements from the right, if it so chooses (e.g. last == foldl (\a b->b) undefined).
Reversing a list is also tail-recursive (it can be implemented using rev = foldl (\ys x -> x : ys) []). On finite lists, that means that left-fold and reverse can be composed to perform a right fold in a tail-recursive way (cf. 1+>(2+>(3+>0)) == ((0<+3)<+2)<+1 ), with a modification to the function f so it reverses the order of its arguments (i.e. foldr f z == foldl (flip f) z . foldl (flip (:)) [] ) , tail-recursively building a representation of the expression that right-fold would build (the extraneous intermediate list structure can be eliminated with the continuation-passing technique, foldr f z xs == foldl (\k x-> k . f x) id xs z).
Another technical point to be aware of in the case of left folds using lazy evaluation is that the new initial parameter is not being evaluated before the recursive call is made. This can lead to stack overflows when one reaches the end of the list and tries to evaluate the resulting potentially gigantic expression. For this reason, such languages often provide a stricter variant of left folding which forces the evaluation of the initial parameter before making the recursive call, in Haskell, this is the foldl' (note the apostrophe, pronounced 'prime') function in the Data.List library. Combined with the speed of tail recursion, such folds are very efficient when lazy evaluation of the final result is impossible or undesirable.
Special folds for nonempty lists
One often wants to choose the identity element of the operation f as the initial value z. When no initial value seems appropriate, for example, when one wants to fold the function which computes the maximum of its two parameters over a non-empty list to get the maximum element of the list, there are variants of foldr and foldl which use the last and first element of the list respectively as the initial value. In Haskell and several other languages, these are called foldr1 and foldl1, the 1 making reference to the automatic provision of an initial element, and the fact that the lists they are applied to must have at least one element.
These folds use type-symmetrical binary operation: the types of both its arguments, and its result, must be the same. Richard Bird in his 2010 book[1] proposes "a general fold function on non-empty lists" foldrn which transforms its last element, by applying an additional argument function to it, into a value of the result type before starting the folding itself, and is thus able to use type-asymmetrical binary operation like the regular foldr to produce a result of type different from the list's elements type.
A Functional Approach to Shifting Certain Array Elements
The following is lifted from a discussion on StackOverflow. It shows a number of ways of implementing only certain "array" elements (where "array" almost always means "vector" in the non-array languages).
I have a Scala app with a list of items with checkboxes so the user select some, and click a button to shift them one position up (left). I decided to write a function to shift elements of some arbitrary type which meet a given predicate. So, if you have these elements:
a b c D E f g h Iand the predicate is "uppercase characters", the function would return this:
a b D E c f g I hIn short, any sequence of contiguous elements that meet the predicate are swapped with the single element at the left of it. I came up with the following ugly imperative implementation. I would like to see a nice, and hopefully readable, functional solution.
def shiftUp[T](a:Array[T], shiftable: T => Boolean) = { val s = new Array[T](a.length) var i = 0 var j = 0 while(i < a.length) { if(!shiftable(a(i)) && i < a.length - 1 && shiftable(a(i+1))) { var ii = i + 1 while(ii < a.length && shiftable(a(ii))) { s(j) = a(ii) ii = ii+1 j = j+1 } s(j) = a(i) i = ii } else { s(j) = a(i) i = i+1 } j = j+1 } s }EDIT: Thanks all, I hope you have enjoyed the exercise! asked Feb 11 '10 at 14:06 by Germán
--
The Scala solutions continue...
Here's a purely functional implementation
def shiftElements[A](l: List[A], pred: A => Boolean): List[A] = { def aux(lx: List[A], accum: List[A]): List[A] = { lx match { case Nil => accum case a::b::xs if pred(b) && !pred(a) => aux(a::xs, b::accum) case x::xs => aux(xs, x::accum) } } aux(l, Nil).reverse }And here's one that uses mutability on the inside to be faster
import scala.collection.mutable.ListBuffer def shiftElements2[A](l: List[A], pred: A => Boolean): List[A] = { val buf = new ListBuffer[A] def aux(lx: List[A]) { lx match { case Nil => () case a::b::xs if pred(b) && !pred(a) => { buf.append(b) aux(a::xs) } case x::xs => { buf.append(x) aux(xs) } } } aux(l) buf.toList }answered Feb 11 '10 at 15:23 by Geoff Reedy
--
A foldLeft solution is proposed:
You could probably do this via a foldLeft (also known as /:):
(str(0).toString /: str.substring(1)) { (buf, ch) => if (ch.isUpper) buf.dropRight(1) + ch + buf.last else buf + ch }It needs work to handle the empty String but:
def foo(Str: String)(p: Char => Boolean) : String = (str(0).toString /: str.substring(1)) { (buf, ch) => if (p(ch) ) buf.dropRight(1) + ch + buf.last else buf + ch } val pred = (ch: Char) => ch.isUpper foo("abcDEfghI")(pred) //prints abDEcfgIhI'll leave it as an exercise as to how to modify this into the array-based solution
answered Feb 11 '10 at 14:59 by oxbow_lakes
--
A more imperative approach:
This is basically an imperative algorithm with a functional style.
def shifWithSwap[T](a: Array[T], p: T => Boolean) = { def swap(i:Int, j:Int) = { val tmp = a(i); a(i) = a(j); a(j) = tmp } def checkAndSwap(i:Int) = i match { case n if n < a.length - 1 && !p(a(i)) && p(a(i+1)) => swap(i, i+1) case _ => } (0 until a.length - 1) map checkAndSwap a }It modifies the Array in place, with a side effect. I think it really does it like the version in the question, except it's easier to read. Imperative does not have to be ugly...
Edit: darn, couldn't fall asleep until I wrote this down (same as above, just more compact):
def shift[T](a: Array[T], p: T => Boolean) = { for (i <- 0 until a.length - 1; if !p(a(i)) && p(a(i+1))) { val tmp = a(i); a(i) = a(i+1); a(i+1) = tmp // swap } a }answered Feb 12 '10 at 7:57 by huynhjl
--
Haskell Solution
A Haskell solution is offered:
I don't know enough to write it in Scala, but this problem is tailor-made for the list functions takeWhile and dropWhile. The idea is that you split the list of items into three parts: • Left part, computed with takeWhile, contains leftmost elements not satisfying the predicate. • Middle part is the group of elements you want to shift left, computed by dropping the left elements and then takeWhile the remainder. • Right part is everything left over; dropWhile the middle elements. Here it is in Haskell:
-- take first group of elements satisfying p and shift left one shift :: (a -> Bool) -> [a] -> [a] shift p l = case reverse left of [] -> l (a:as) -> reverse as ++ middle ++ a : shift p right where left = takeWhile (not . p) l -- could be done with List.break notLeft = dropWhile (not . p) l middle = takeWhile p notLeft -- could be done with List.span right = dropWhile p notLeftAnd here's a single unit test:
*Shiftup> shift (>9) [1, 2, 3, 44, 55, 6, 7, 8] [1,2,44,55,3,6,7,8]Haskell programmers might use List.break or List.span to combine calls to takeWhile and dropWhile, but I'm not sure if Scala has these things. Besides, takeWhile and dropWhile are nice meaningful names, whereas I at least find break and span less perspicuous.
EDIT: fixed recursive call to do shift p right instead of right to shift up all groups.
answered Feb 12 '10 at 1:55 by Norman Ramsey
--
Some J Solutions
In constrast to the 8- to 24-line solutions above, here are a couple of solutions in J weighing in at one or two lines apiece.
Here is one I offered:
('abcdefghijklmnopqrstuvwxyz';'ABCDEFGHIJKLMNOPQRSTUVWXYZ') (4 : '(y#~y e. >1{x)([: I. '' ''= ])} }._1&|.&.((1,~y e. >0{x)&#)y,'' ''') 'abcDEfghI'
abDEcfgIh
Explanation of First J Solution
Let’s break this into named pieces for easier comprehension. The final string “abDEcfgIh” is the result of applying a function to the string “abcDEfghI” which is the right argument to the function. The pair of alphabets constitute the left argument to the function (which is the part beginning “(4 : …”). So, instead of the 2-element vector of boxed strings, we could name each one individually:
'lc uc'=. 'abcdefghijklmnopqrstuvwxyz';'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
Now that we have two variables “lc” and “uc” for the lower-case and upper-case alphabets, let’s examine the body of the function in detail. Taking a logically coherent chunk from the right end, since this would be evaluated first, we could name this like so:
rmUCshift=: 4 : 0
}._1&|.&.((1,~y e. >0{x)&#)y,' '
)
This defines “rmUCshift” as something that requires a right and left argument (the “4 :” specifies this) with the body beginning on the next line and continuing to the bare closing paren. The “4 : 0” form, followed by the body, is a variant of the “4 : ‘body’” form shown initially. This verb rmUCshift can be invoked independently like this:
(lc;'') rmUCshift 'abcDEfghI' NB. Remove upper-case, shift, then insert ab cfg h NB. spaces where the upper-case would now be.
The invocation is indented three spaces and the output immediately follows it. The left argument (lc;) is a two-element vector with the empty array specified as the second element because it’s not used in this piece of the code – we could have used any value after the semicolon but the two single quotes are easy to type.
The next pieces to name are these (definitions followed by examples):
ixSpaces=: [:I.' '=]
ixSpaces 'ab cfg h'
2 3 7
onlyUC=: 4 : 'y#~y e.>1{x'
('';uc) onlyUC 'abcDEfghI'
DEI
Combining these named pieces together gives us this:
(lc;uc) (4 : '(x onlyUC y)(ixSpaces x rmUCshift y)}x rmUCshift y') 'abcDEfghI' abDEcfgIh
However, the repetition of “x rmUCshift y” is unnecessary and can be simplified to give us this:
(lc;uc) (4 : '(x onlyUC y) ((ixSpaces ]) } ]) x rmUCshift y') 'abcDEfghI' abDEcfgIh
Another J Solution
This similarly concise version comes from Marshall Lochbaum:
from Marshall Lochbaum mwlochbaum@gmail.com via srs.acm.org date Tue, Aug 9, 2011 at 2:01 PM
Here is the best code I have for shifting:
'lc uc' =. +&(i.26)&.(a.&i.)"0 'aA' shift =. /: (i.@# - ] - (1 |. ([+*)/\.) * 0 ,~ 2&(</\))@:(e.&uc) shift 'abcDEfghI' abDEcfgIh
It's still a little complicated. Another option which I'm looking at now is to select instead of sorting: then all spaces with capitals in front of them take that capital, and all of the last capitals (capitals that come before lowercase letters) take the last uppercase before that block of capitals.
Marshall
Avoiding One-off Errors by Sliding
This is another discussion lifted from StackOverflow.
One of the advantages of not handling collections through indices is to avoid off-by-one errors. That's certainly not the only advantage, but it is one of them.
Now, I often use sliding in some algorithms in Scala, but I feel that it usually results in something very similar to the off-by-one errors, because a sliding of m elements in a collection of size n has size n - m + 1 elements. Or, more trivially, list sliding 2 is one element shorter than list.
The feeling I get is that there's a missing abstraction in this pattern, something that would be part sliding, part something more -- like foldLeft is to reduceLeft. I can't think of what that might be, however. Can anyone help me find enlightenment here?
UPDATE
Since people are not clear on what I'm talking, let's consider this case. I want to capitalize a string. Basically, every letter that is not preceded by a letter should be upper case, and all other letters should be lower case. Using sliding, I have to special case either the first or the last letter. For example:
def capitalize(s: String) = s(0).toUpper +: s.toSeq.sliding(2).map { case Seq(c1, c2) if c2.isLetter => if (c1.isLetter) c2.toLower else c2.toUpper case Seq(_, x) => x }.mkStringasked yesterday by Daniel C. Sobral / 58.1k793185 / 92% accept rate
Some J Solutions
This is the sort of problem nicely-suited to an array-oriented functional language like J. Basically, we generate a boolean with a one corresponding to the first letter of each word. To do this, we start with a boolean marking the spaces in a string. For example (lines indented three spaces are inputs; results are flush with left margin):
str=. 'now is the time' NB. Example w/extra spaces for interest
]whspc=. ' '=str NB. Mark where spaces are=1
0 0 0 1 1 0 0 1 1 0 0 0 1 1 1 1 0 0 0 0
Verify that `(*.-.)` ("and not") returns one only for "1 0":
]tt=. #:i.4 NB. Truth table
0 0
0 1
1 0
1 1
(*.-.)/"1 tt NB. Apply to one-dimensional (rows)
0 0 1 0 NB. As hoped.
Slide our tacit function across pairs in the boolean:
2(*.-.)/\whspc NB. Apply to 2-ples
0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 0
But this doesn't handle the edge condition of the initial letter, so force a one into the first position. This actually helps as the reduction of 2-ples left us one short. Here we compare lengths of the original boolean and the target boolean:
#whspc
20
#1,2(*.-.)/\whspc
20
1,2(*.-.)/\whspc
1 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 0
We get uppercase by using the index into the lowercase vector to select from the uppercase vector (after defining these two vectors):
'lc uc'=. 'abcdefghijklmnopqrstuvwxyz';'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
(uc,' '){~lc i. str
NOW IS THE TIME
Check that insertion by boolean gives correct result:
(1,2(*.-.)/\whspc) } str,:(uc,' '){~lc i. str
Now Is The Time
Now is the time to combine all this into one statement:
(1,2(*.-.)/\' '=str) } str,:(uc,' '){~lc i. str
Now Is The Time
--
from Boyko Bantchev boykobb@gmail.com via srs.acm.org to Programming forum <programming@jsoftware.com> date Tue, Aug 9, 2011 at 7:47 AM subject Re: [Jprogramming] Materials for NYCJUG meeting today - Tuesday 8/9 at Empire State Building
Living no less than 7 time zones from NYC, I am not going to attend the meeting anyway :) But browsing through some of the materials, part of them, in my opinion, hardly demonstrate any advantages of coding in J (if they are meant to do that at all). Here are comments on two titles.
One Off by Sliding
The proposed J solution solves a somewhat restricted problem: it appears to be specialized on strings rather than applying to any sequence. And regarding the string case -- which is meant by the original poster to be merely an illustration -- the J program gets even more specialized by interpreting the phrase `not preceded by a letter' to mean `possibly preceded by a space character'. In fact, it even works erroneously if the argument string contains something else besides letters and space chars. More importantly, the J program does not address the deeper problem as stated by the original poster, i.e. to find a form of abstraction that would not require special-casing the first (or last) item as the sequence gets shortened.
A Functional Approach to Shifting Certain Array Elements
Once more, the J program in this article solves a restricted problem and not the one originally posted. The latter requires that the solution deals with sequences of arbitrary type, to which it should be able to apply any relevant predicate. The J program only works for strings, and actually only for strings of letters (ending abnormally for other strings). Moreover, the check it does (for upper-case letters) is `wired-in' in it. I should add that, even though the J program solves a simpler problem, its size and complexity hardly make it attractive, compared to the simple and direct imperative solution by `huynhjl'. [see below] Of course, most other solutions were unnecessarily complicated, too. For a contrast, in Haskell one would write, instead:
shift p zs = f zs where f (x:zs@(y:zs')) | not (p y) = x : f zs | p x = x: y : f zs' | otherwise = y : f (x:zs') f zs = zsOr, avoiding explicit recursion:
shift p xs = reverse $ maybe as (:as) m where (as,m) = foldl f ([],Nothing) xs f (as,m) x = if p x then (x:as,m) else (maybe as (:as) m, Just x)
--
Direct Imperative Solution by `huynhjl'
In your example, I think the code is made more complex because, you basically want to do a map but working with sliding which introduces edge conditions in a way that doesn't work nicely. I think a fold left with an accumulator that remembers the relevant state may be easier conceptually:
def capitalize2(s: String) = (("", true) /: s){ case ((res, notLetter), c) =>
(res + (if (notLetter) c.toUpper else c.toLower), !c.isLetter)
}._1
I think this could be generalized so that notLetter could remember n elements where n is the size of the sliding window.
answered yesterday / huynhjl / 7,3801726
--
from Devon McCormick devonmcc@gmail.com to Programming forum <programming@jsoftware.com> date Tue, Aug 9, 2011 at 11:54 AM subject Re: [Jprogramming] Materials for NYCJUG meeting today - Tuesday 8/9 at Empire State Building
Thanks for your comments.
These were done to come up with some examples to present J to a group of functional programmers. I'm hoping to provide J equivalents alongside solutions in other languages with which people may be more familiar. I'll take a look at coming up with a solution to hew more closely to the problem spec but I'd like to use as much "raw" J as possible and not rely on equivalents like the apparent built-ins "isLetter" and "toLower" in some of the other solutions.
I wasn't very happy with the J code for the shifting problem as it does seem too complicated for such a simple problem.
In the "One Off by Sliding" example, I'm trying to illustrate a different way to avoid looping by using arrays rather than recursion which seems to be a common iteration method in functional languages. Ideally, I'd like an example where I can show both an array-based solution and work in some of J's iterative methods as well - things like scan and the power conjunction.
Meeting Materials
From here: File:Why Minimal Guidance Instruction Does Not Work kirschner Sweller Clark.pdf
File:Poker Simulation So Far.pdf
File:Comparison of Fold and Map in Various Languages.pdf
File:A Functional Approach to Shifting Certain Array Elements.pdf
File:Sketches of Poker Simulation Strategy.pdf
File:APL images - family and APL-360 cover design.pdf
File:Excerpts from Language Size from Gabriel's Patterns Of Software.pdf